
GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
Paper • 2507.01006 • Published • 255
Includes Unsloth chat template fixes!
Forllama.cpp, use--jinja
Unsloth Dynamic 2.0 achieves superior accuracy & outperforms other leading quants.



📖 View the GLM-4.1V-9B-Thinking paper.
💡 Try the Hugging Face or ModelScope online demo for GLM-4.1V-9B-Thinking.
📍 Using GLM-4.1V-9B-Thinking API at Zhipu Foundation Model Open Platform
Vision-Language Models (VLMs) have become foundational components of intelligent systems. As real-world AI tasks grow increasingly complex, VLMs must evolve beyond basic multimodal perception to enhance their reasoning capabilities in complex tasks. This involves improving accuracy, comprehensiveness, and intelligence, enabling applications such as complex problem solving, long-context understanding, and multimodal agents.
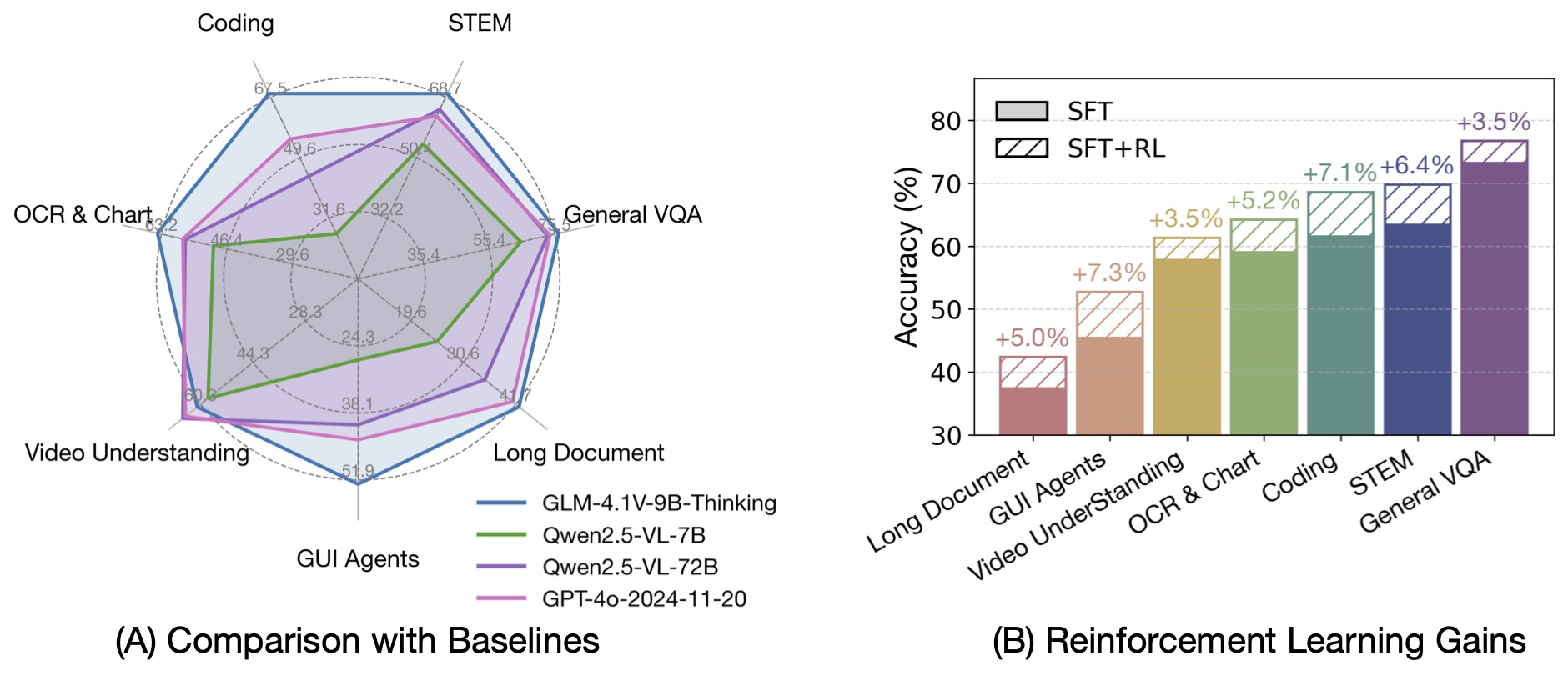
Based on the GLM-4-9B-0414 foundation model, we present the new open-source VLM model GLM-4.1V-9B-Thinking, designed to explore the upper limits of reasoning in vision-language models. By introducing a "thinking paradigm" and leveraging reinforcement learning, the model significantly enhances its capabilities. It achieves state-of-the-art performance among 10B-parameter VLMs, matching or even surpassing the 72B-parameter Qwen-2.5-VL-72B on 18 benchmark tasks. We are also open-sourcing the base model GLM-4.1V-9B-Base to support further research into the boundaries of VLM capabilities.
Compared to the previous generation models CogVLM2 and the GLM-4V series, GLM-4.1V-Thinking offers the following improvements:
By incorporating the Chain-of-Thought reasoning paradigm, GLM-4.1V-9B-Thinking significantly improves answer accuracy, richness, and interpretability. It comprehensively surpasses traditional non-reasoning visual models. Out of 28 benchmark tasks, it achieved the best performance among 10B-level models on 23 tasks, and even outperformed the 72B-parameter Qwen-2.5-VL-72B on 18 tasks.

This is a simple example of running single-image inference using the transformers library.
First, install the transformers library from source:
pip install git+https://github.com/huggingface/transformers.git
Then, run the following code:
from transformers import AutoProcessor, Glm4vForConditionalGeneration
import torch
MODEL_PATH = "THUDM/GLM-4.1V-9B-Thinking"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"url": "https://upload.wikimedia.org/wikipedia/commons/f/fa/Grayscale_8bits_palette_sample_image.png"
},
{
"type": "text",
"text": "describe this image"
}
],
}
]
processor = AutoProcessor.from_pretrained(MODEL_PATH, use_fast=True)
model = Glm4vForConditionalGeneration.from_pretrained(
pretrained_model_name_or_path=MODEL_PATH,
torch_dtype=torch.bfloat16,
device_map="auto",
)
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=8192)
output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False)
print(output_text)
For video reasoning, web demo deployment, and more code, please check our GitHub.
Base model
zai-org/GLM-4-9B-0414