Quantized 4-bit models
Collection
Large model quantized with post-quantization performance very close to the original models, allowing it to run on reasonable infrastructure. • 9 items • Updated • 1
Converted version of CodeLlama-7b to 4-bit using bitsandbytes. For more information about the model, refer to the model's page.
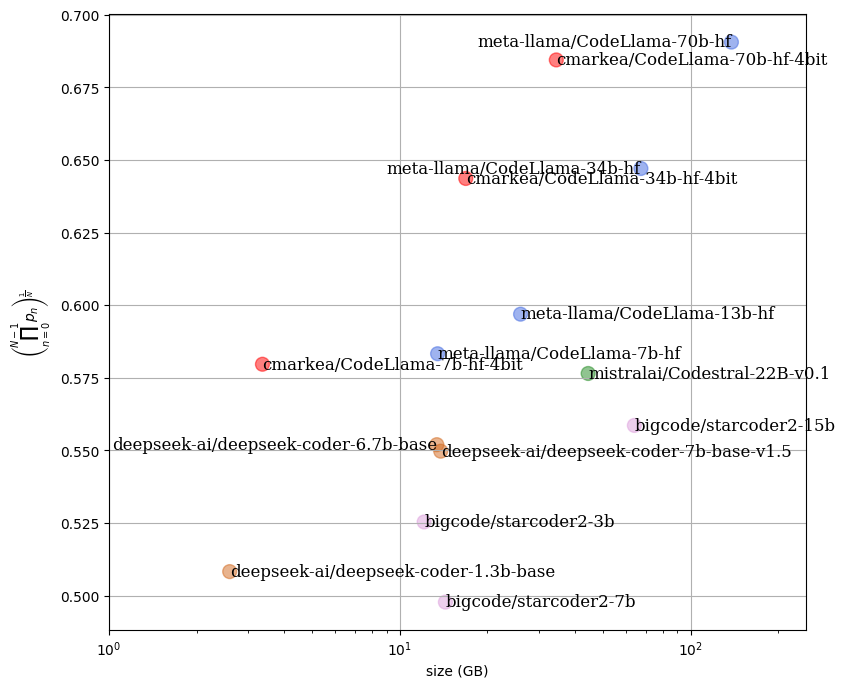
In the following figure, we can see the impact on the performance of a set of models relative to the required RAM space. It is noticeable that the quantized models have equivalent performance while providing a significant gain in RAM usage.