
MiniMax-M2.7 REAP
Collection
6 items • Updated • 1
This AWQ 4-bit export was benchmarked locally with vllm against gsm8k_platinum_cot_llama using the MiniMax-recommended sampling parameters (temperature=1.0, top_p=0.95, top_k=40) and the default system prompt:
You are a helpful assistant. Your name is MiniMax-M2.7 and is built by MiniMax.
vllm serve bullerwins/MiniMax-M2.7-REAP-172B-AWQ-4bit \
--served-model-name MiniMax-M2.7 \
--max-num-seqs 32 \
--max-model-len auto \
--gpu-memory-utilization 0.9 \
-tp 8 \
--enable-expert-parallel \
--enable-auto-tool-choice \
--tool-call-parser minimax_m2 \
--reasoning-parser minimax_m2 \
--trust-remote-code \
--host 0.0.0.0 \
--port 5000
source .venv/bin/activate
lm_eval run \
--model local-chat-completions \
--tasks gsm8k_platinum_cot_llama \
--model_args "model=MiniMax-M2.7,max_length=196608,base_url=http://127.0.0.1:5000/v1/chat/completions,num_concurrent=32,max_retries=3,tokenized_requests=False,tokenizer_backend=None,timeout=2400,eos_string=</s>" \
--apply_chat_template \
--fewshot_as_multiturn \
--system_instruction "You are a helpful assistant. Your name is MiniMax-M2.7 and is built by MiniMax." \
--gen_kwargs do_sample=True temperature=1.0 top_p=0.95 top_k=40 max_gen_toks=8192 \
--num_fewshot 8 \
--seed 42 \
--output_path benchmark_results/minimax_m27_gsm8k_<runstamp> \
--log_samples
| Variant | Backend | Seed(s) | Flexible EM | Strict EM | Notes |
|---|---|---|---|---|---|
| MiniMax-M2.7-REAP-172B-AWQ-4bit | Local vLLM | 42 | 0.9711 +- 0.0048 | 0.9711 +- 0.0048 | Full run, 1209 examples |
| MiniMax-M2.7-REAP-172B-AWQ-4bit | Local vLLM | 1234 | 0.9702 +- 0.0049 | 0.9694 +- 0.0050 | Full run, 1209 examples |
| MiniMax-M2.7-REAP-172B-AWQ-4bit | Local vLLM | 5678 | 0.9727 +- 0.0047 | 0.9711 +- 0.0048 | Full run, 1209 examples |
| MiniMax-M2.7-REAP-172B-AWQ-4bit | Local vLLM | mean of 3 runs | 0.9713 | 0.9705 | Mean across seeds 42 / 1234 / 5678 |
| Variant | Backend | Seed(s) | Flexible EM | Strict EM | Notes |
|---|---|---|---|---|---|
| MiniMax-M2.7 original weights | OpenRouter | 42 | 0.9744 +- 0.0045 | 0.9735 +- 0.0046 | 9 late null content generations |
| MiniMax-M2.7 original weights | OpenRouter | 1234 | 0.9702 +- 0.0049 | 0.9686 +- 0.0050 | 10 late null content generations; runtime about 1:22:21 |
| MiniMax-M2.7 original weights | OpenRouter | mean of 2 runs | 0.9723 | 0.9711 | Mean across seeds 42 / 1234 |
| MiniMax-M2.7-REAP-172B-AWQ-4bit | Local vLLM | mean of 3 runs | 0.9713 | 0.9705 | About 0.10 flexible / 0.06 strict points below the two-run OpenRouter mean |
OpenRouter reference command:
source .venv/bin/activate
OPENAI_API_KEY="$OPENROUTER_API_KEY" lm-eval run \
--model local-chat-completions \
--tasks gsm8k_platinum_cot_llama \
--model_args "model=minimax/minimax-m2.7,base_url=https://openrouter.ai/api/v1/chat/completions,num_concurrent=2,max_retries=3,tokenized_requests=False,tokenizer_backend=None,timeout=1200,max_length=32768,seed=42" \
--apply_chat_template \
--fewshot_as_multiturn \
--system_instruction "You are a helpful assistant. Your name is MiniMax-M2.7 and is built by MiniMax." \
--gen_kwargs do_sample=True temperature=1.0 top_p=0.95 top_k=40 max_gen_toks=1024 \
--num_fewshot 8 \
--seed 42 \
--output_path results/openrouter_minimax_m27_gsm8k_platinum_full \
--log_samples
MiniMax-M2.7 is our first model deeply participating in its own evolution. M2.7 is capable of building complex agent harnesses and completing highly elaborate productivity tasks, leveraging Agent Teams, complex Skills, and dynamic tool search. For more details, see our blog post.
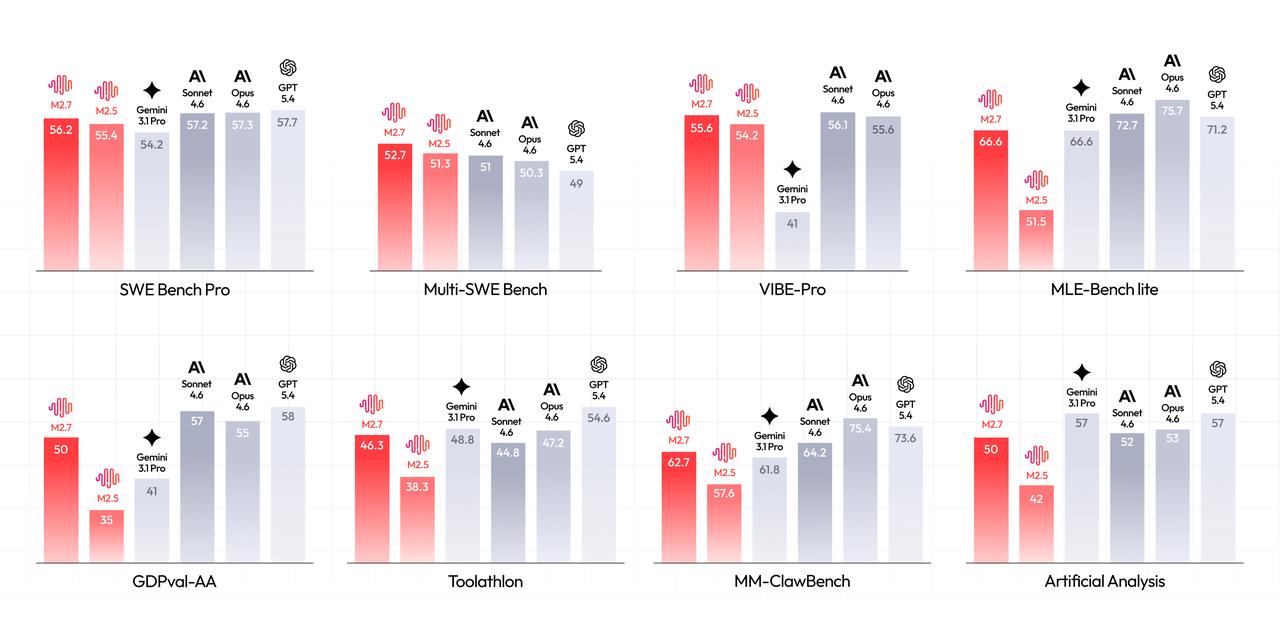
M2.7 initiates a cycle of model self-evolution: during development, we let the model update its own memory, build dozens of complex skills for RL experiments, and improve its own learning process based on experiment results. An internal version of M2.7 autonomously optimized a programming scaffold over 100+ rounds — analyzing failure trajectories, modifying code, running evaluations, and deciding to keep or revert — achieving a 30% performance improvement. On MLE Bench Lite (22 ML competitions), M2.7 achieved a 66.6% medal rate, second only to Opus-4.6 and GPT-5.4.


M2.7 delivers outstanding real-world programming capabilities spanning log analysis, bug troubleshooting, refactoring, code security, and machine learning. Beyond code generation, M2.7 demonstrates strong system-level reasoning — correlating monitoring metrics, conducting trace analysis, verifying root causes in databases, and making SRE-level decisions. Using M2.7, we have reduced live production incident recovery time to under three minutes on multiple occasions.
On SWE-Pro, M2.7 achieved 56.22%, matching GPT-5.3-Codex, with even stronger performance on real-world engineering benchmarks: SWE Multilingual (76.5) and Multi SWE Bench (52.7). On VIBE-Pro (55.6%), M2.7 is nearly on par with Opus 4.6. On Terminal Bench 2 (57.0%) and NL2Repo (39.8%), M2.7 demonstrates deep understanding of complex engineering systems. M2.7 also supports native Agent Teams for multi-agent collaboration with stable role identity and autonomous decision-making.

M2.7 achieved an ELO score of 1495 on GDPval-AA (highest among open-weight models), surpassing GPT5.3. It handles Word, Excel, and PPT with high-fidelity multi-round editing, producing editable deliverables. On Toolathon, M2.7 reached 46.3% accuracy (global top tier), and maintains 97% skill compliance across 40+ complex skills on MM Claw. On the MM Claw end-to-end benchmark, M2.7 achieved 62.7%, close to Sonnet 4.6.
M2.7 features strengthened character consistency and emotional intelligence. We open-sourced OpenRoom, an interactive demo that places AI interaction within a Web GUI space with real-time visual feedback and scene interactions. Try it at openroom.ai.
Download the model from HuggingFace repository: https://huggingface.co/MiniMaxAI/MiniMax-M2.7
We recommend using the following inference frameworks (listed alphabetically) to serve the model:
We recommend using SGLang to serve MiniMax-M2.7. Please refer to our SGLang Deployment Guide.
We recommend using vLLM to serve MiniMax-M2.7. Please refer to our vLLM Deployment Guide.
We recommend using Transformers to serve MiniMax-M2.7. Please refer to our Transformers Deployment Guide.
You also can get model weights from modelscope.
MiniMax M2.7 is also available on NVIDIA NIM Endpoint.
We recommend using the following parameters for best performance: temperature=1.0, top_p = 0.95, top_k = 40. Default system prompt:
You are a helpful assistant. Your name is MiniMax-M2.7 and is built by MiniMax.
Please refer to our Tool Calling Guide.
Contact us at model@minimax.io.
Base model
MiniMaxAI/MiniMax-M2.7