
Multi Modal Models
Collection
6 items • Updated • 1
LLM-jp-4-VL 9B beta is a vision-language model developed by LLM-jp.
It is built upon llm-jp/llm-jp-4-8b-instruct and demonstrates competitive performance on Japanese benchmarks.
The model architecture is inspired by InternVL3.0 and consists of a language model, a vision encoder, and a lightweight projector.
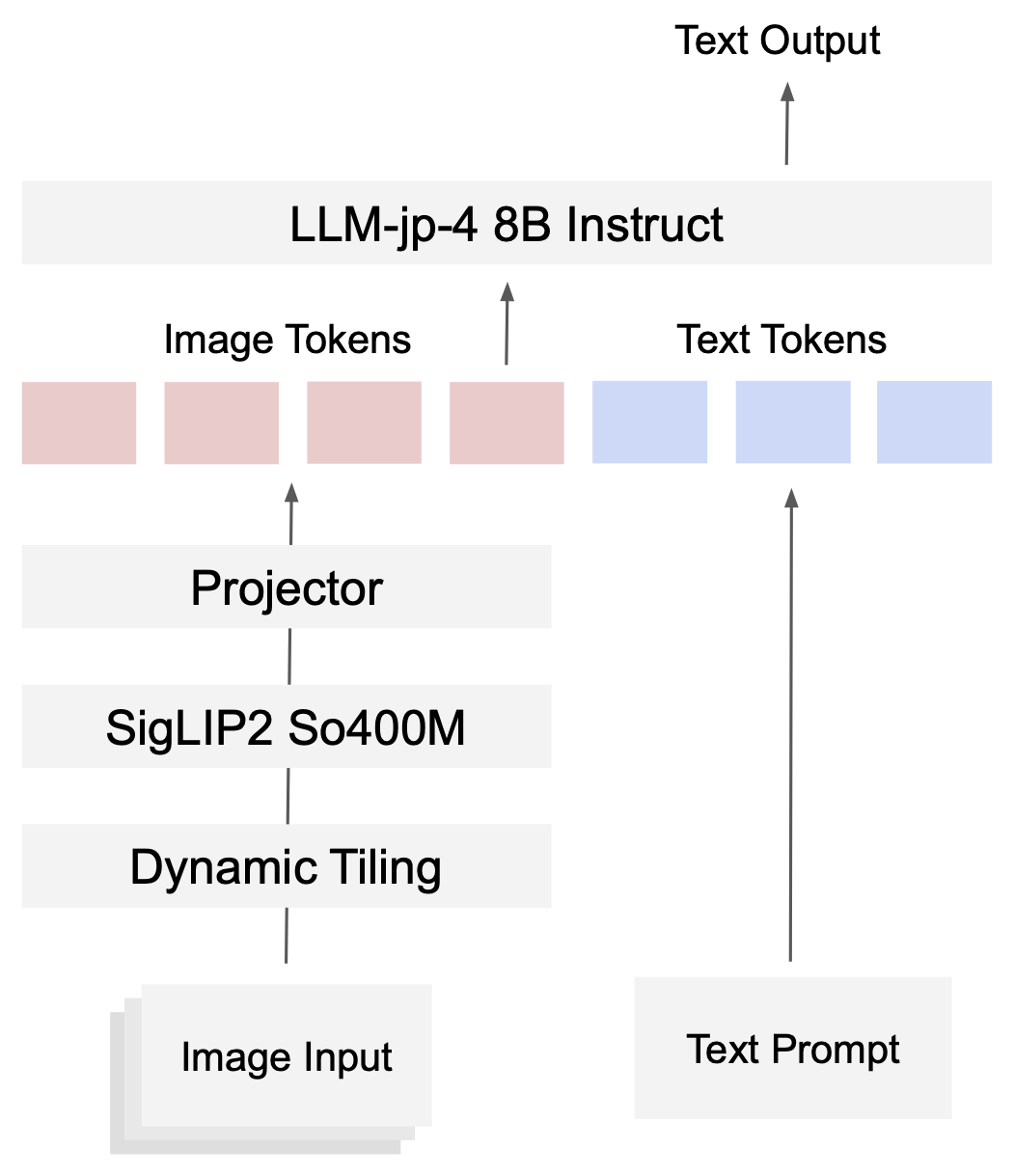
To support high-resolution images, we adopt dynamic tiling, where each image is adaptively split into tiles based on its aspect ratio. By encoding these tiles independently and concatenating them as image tokens, the model can effectively handle fine-grained visual details that would otherwise be lost under fixed-resolution encoding.
We adopt a customized chat template based on an extension of the OpenAI Harmony format.
In this template, a sequence of image tokens is wrapped with special tokens <|image_start|> and <|image_end|>, and inserted into the user message. An example input is shown below:
<|start|>system<|message|>{system_message}<|end|>
<|start|>user<|message|><|image_start|><|image_pad|>...<|image_pad|><|image_end|>What is the animal shown in this image?<|end|>
<|start|>assistant<|channel|>final<|message|>It is a cat.<|return|>
The training data consists of a mixture of two large-scale datasets:
We train the model using a single-stage training scheme for 90,000 steps (approximately 3 epochs, corresponding to 180B tokens including image tokens).
We use different maximum learning rates for each component, with 2e-5 for both the language model and vision encoder, and 1e-4 for the projector.
The learning rate follows the Warmup–Stable–Decay (WSD) schedule, with a warmup phase of 2,000 steps, followed by stable training, and linear decay starting after 80% of the total training steps.
We evaluate the model using simple-evals-mm, our evaluation framework for VLMs.
For English evaluation, we use 10 widely adopted benchmarks, including AI2D, BLINK, ChartQA, DocVQA, InfoVQA, MMMU, OKVQA, RealWorldQA, ScienceQA, and TextVQA.
For Japanese evaluation, we use another 10 benchmarks, including JAMMEval collection (CC-OCR-JA-Refined, CVQA-JA-Refined, Heron-Bench-Refined, JA-Multi-Image-VQA-Refined, JA-VLM-Bench-Refined, JDocQA-Refined, and JGraphQA-Refined), as well as BusinessSlideVQA, JMMMU, and MECHA-ja.
We compare our model against the following baselines: Qwen3-VL-8B-Instruct, InternVL3.5-8B, and Sarashina-2.2-Vision-3B.
Our model achieves performance on par with Qwen3-VL-8B-Instruct on average across 10 Japanese tasks, while using significantly fewer multimodal post-training tokens (180B vs. over 2T for Qwen3-VL).
Training curve on Avg, JA Avg, and EN Avg

Japanese benchmark results

English benchmark results

Install requirements.
uv add "torch==2.8.0" "transformers==4.57.0" "flash-attn==2.8.3" "pillow==11.3.0"
Below is the sample code to run the model.
import torch
from transformers import AutoProcessor, AutoModel
model_id = "llm-jp/llm-jp-4-vl-9B-beta"
# load model
model = (
AutoModel.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
use_flash_attn=True,
)
.eval()
.cuda()
)
processor = AutoProcessor.from_pretrained(model_id, trust_remote_code=True)
def generate(messages, max_new_tokens=256, temperature=0.0):
inputs = processor.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
if "pixel_values" in inputs:
inputs["pixel_values"] = inputs["pixel_values"].to(dtype=model.dtype)
outputs = model.generate(
**inputs,
max_new_tokens=max_new_tokens,
do_sample=temperature > 0,
temperature=temperature if temperature > 0 else None,
)
text = processor.decode(outputs[0], skip_special_tokens=False)
text = text.replace("<|channel|>final<|message|>", "")
text = text.replace("<|return|>", "")
text = text.replace(processor.tokenizer.eos_token, "")
return text.strip()
# -----------------------
# 1. Text-only
# -----------------------
messages = [
{
"role": "user",
"content": [{"type": "text", "text": "富士山について簡潔に説明してください。"}],
}
]
print(generate(messages))
# 富士山は、日本最高峰の山で、標高3,776メートルです。静岡県と山梨県にまたがっており、世界遺産にも登録されています。
# -----------------------
# 2. Single image
# -----------------------
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "assets/kaonashi.jpg"},
{"type": "text", "text": "このキャラクターの名前は何ですか?"},
],
}
]
print(generate(messages))
# カオナシ
# -----------------------
# 3. Multi-image
# -----------------------
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "assets/Shiba_inu.jpg"},
{"type": "image", "image": "assets/yesoensis.jpg"},
{"type": "text", "text": "それぞれの動物の名前を教えてください。"},
],
}
]
print(generate(messages))
# 柴犬と鹿です。
# -----------------------
# 4. Multi-turn example
# -----------------------
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "assets/kaonashi.jpg"},
{
"type": "text",
"text": "このキャラクターが登場する映画のタイトルは何ですか?",
},
],
},
{
"role": "assistant",
"content": [{"type": "text", "text": "千と千尋の神隠し"}],
},
{
"role": "user",
"content": [{"type": "text", "text": "監督は誰ですか?"}],
},
]
print(generate(messages))
# 宮崎駿
For more details, please refer to the official GitHub repository: https://github.com/llm-jp/llm-jp-4-vl
Apache License 2.0
FineVision, which is used to train this model, is a curated dataset aggregated from multiple existing datasets.
Some portions include data derived from outputs generated by proprietary models (e.g., OpenAI, Anthropic, and other closed-source systems).
Users must comply with the applicable terms of use of those models when using this model.
If you find our work useful, please consider citing the following papers:
@misc{sugiura2026jaglebuildinglargescalejapanese,
title={Jagle: Building a Large-Scale Japanese Multimodal Post-Training Dataset for Vision-Language Models},
author={Issa Sugiura and Keito Sasagawa and Keisuke Nakao and Koki Maeda and Ziqi Yin and Zhishen Yang and Shuhei Kurita and Yusuke Oda and Ryoko Tokuhisa and Daisuke Kawahara and Naoaki Okazaki},
year={2026},
eprint={2604.02048},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.02048},
}
@misc{sugiura2026jammevalrefinedcollectionjapanese,
title={JAMMEval: A Refined Collection of Japanese Benchmarks for Reliable VLM Evaluation},
author={Issa Sugiura and Koki Maeda and Shuhei Kurita and Yusuke Oda and Daisuke Kawahara and Naoaki Okazaki},
year={2026},
eprint={2604.00909},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.00909},
}
Base model
llm-jp/llm-jp-4-8b-instruct