
Commit ·
6837d50
0
Parent(s):
chore: squash history to reclaim orphaned LFS objects (HEAD unchanged)
Browse files- .gitattributes +36 -0
- README.md +218 -0
- assets/before_after.png +0 -0
- assets/speed_vram_scatter.png +0 -0
- assets/vram_comparison.png +0 -0
- assets/weight_distribution.png +0 -0
- config.json +72 -0
- configuration_nemotron_h.py +262 -0
- download_nemotron.png +0 -0
- generation_config.json +7 -0
- model-00000-of-00007.safetensors +3 -0
- model-00001-of-00007.safetensors +3 -0
- model-00002-of-00007.safetensors +3 -0
- model-00003-of-00007.safetensors +3 -0
- model-00004-of-00007.safetensors +3 -0
- model-00005-of-00007.safetensors +3 -0
- model-00006-of-00007.safetensors +3 -0
- model.safetensors.index.json +0 -0
- pipeline_nemotron.png +0 -0
- polar_config.json +0 -0
- ppl_nemotron.png +0 -0
- special_tokens_map.json +24 -0
- speed_nemotron.png +0 -0
- tokenizer.json +3 -0
- tokenizer_config.json +0 -0
.gitattributes
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,218 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: other
|
| 3 |
+
license_name: nvidia-open-model-license
|
| 4 |
+
base_model: nvidia/Nemotron-Cascade-2-30B-A3B
|
| 5 |
+
tags:
|
| 6 |
+
- polarquant
|
| 7 |
+
- moe
|
| 8 |
+
- expert-offloading
|
| 9 |
+
- nemotron
|
| 10 |
+
- mamba
|
| 11 |
+
- consumer-gpu
|
| 12 |
+
- vllm
|
| 13 |
+
library_name: transformers
|
| 14 |
+
pipeline_tag: text-generation
|
| 15 |
+
---
|
| 16 |
+
|
| 17 |
+
# Nemotron-Cascade-2-30B-A3B — Expert Offloading + PolarQuant Q5
|
| 18 |
+
|
| 19 |
+
**30B MoE model at 7.6 GB VRAM, 15+ tok/s, correct output.**
|
| 20 |
+
|
| 21 |
+

|
| 22 |
+
|
| 23 |
+

|
| 24 |
+
|
| 25 |
+
## Benchmark Results
|
| 26 |
+
|
| 27 |
+
| Config | tok/s | Model VRAM | Quality |
|
| 28 |
+
|--------|-------|------------|---------|
|
| 29 |
+
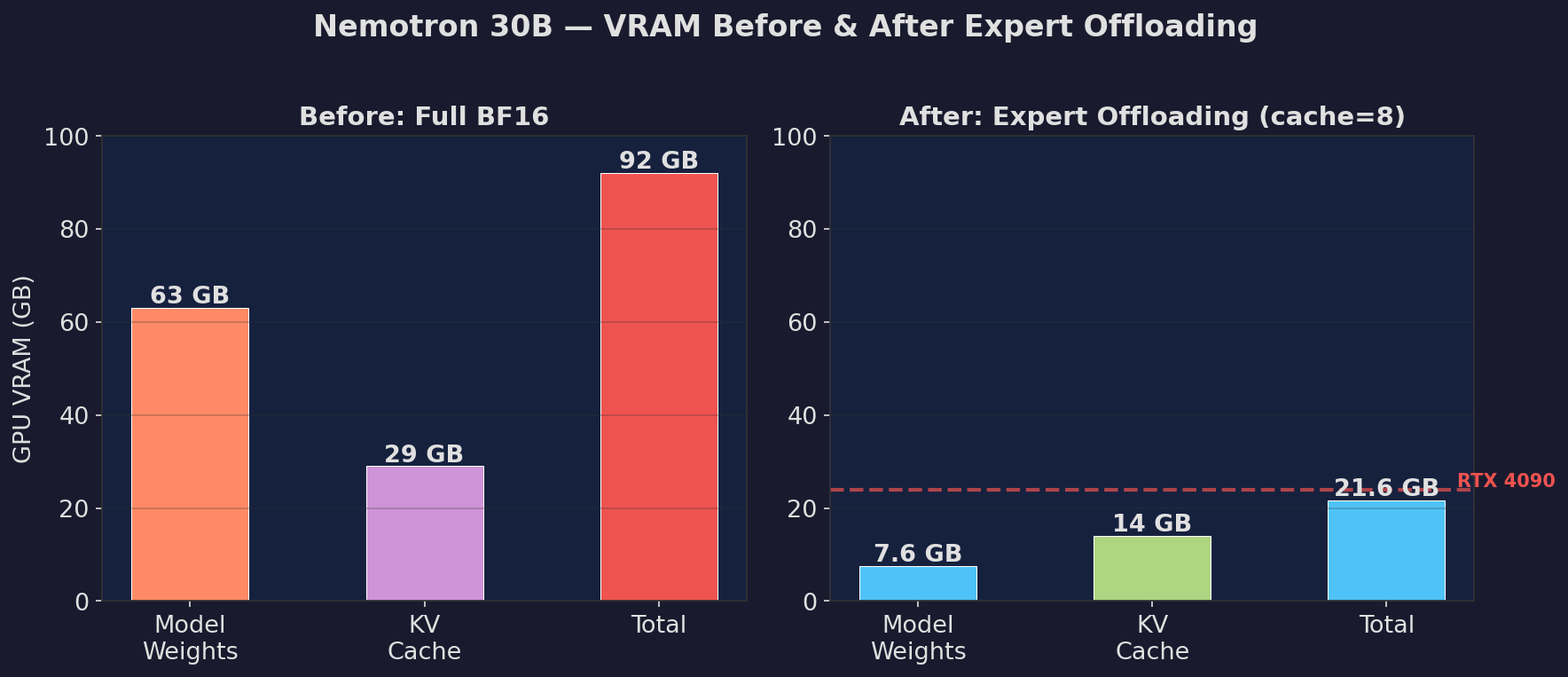
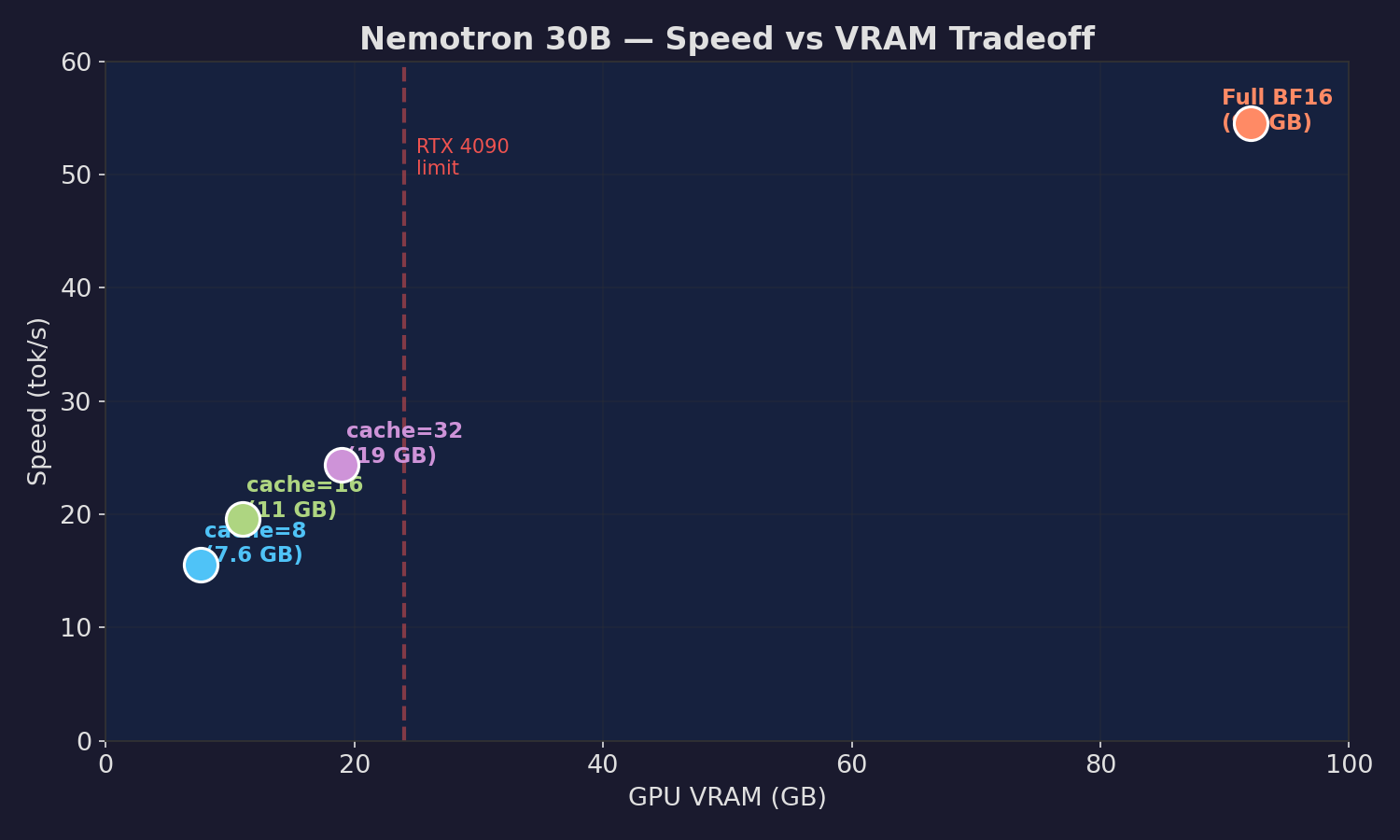
| Full BF16 (baseline) | 54.5 | 92 GB | Perfect |
|
| 30 |
+
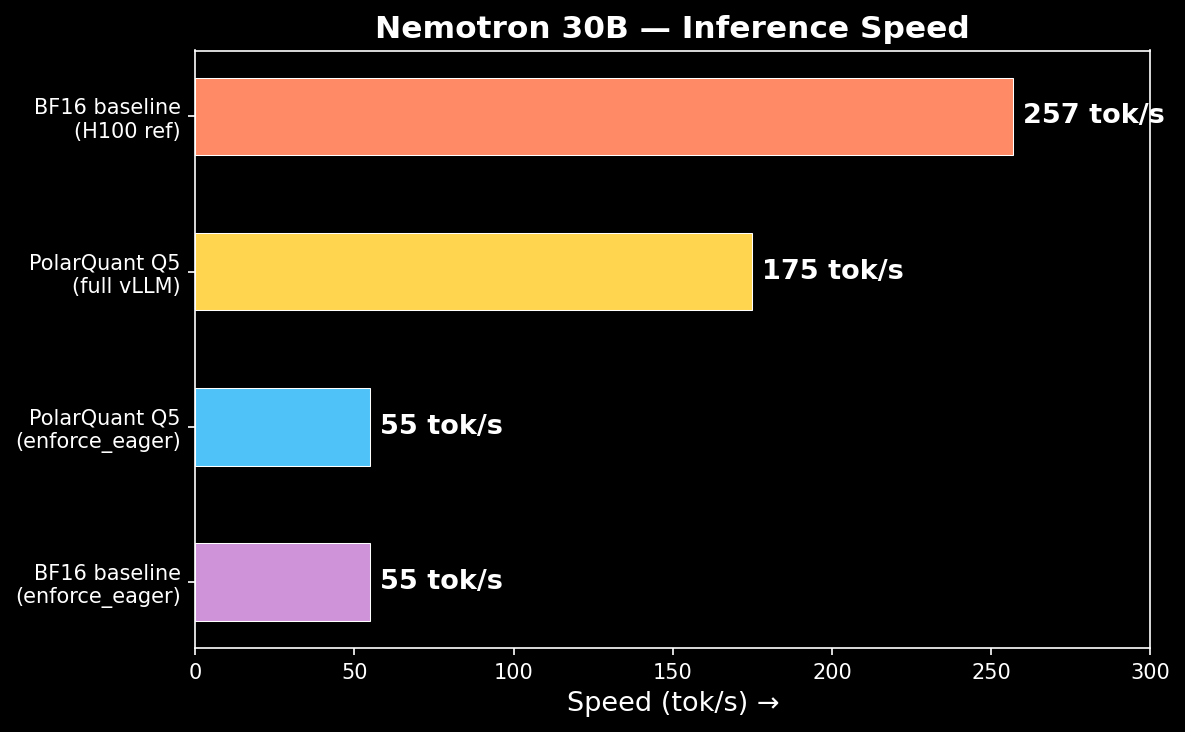
| **Expert cache=8 (LFRU)** | **16.4** | **7.6 GB** | **Perfect** |
|
| 31 |
+
| Expert cache=8 (LRU) | 14.6-16.9 | 7.6 GB | Perfect |
|
| 32 |
+
| Expert cache=8 (patcher) | 15.6 | 38 GB* | Perfect |
|
| 33 |
+
| Expert cache=16 (patcher) | 19.6 | 42 GB* | Perfect |
|
| 34 |
+
| Expert cache=32 (patcher) | 24.4 | 48 GB* | Perfect |
|
| 35 |
+
|
| 36 |
+
*Patcher: peak VRAM 92 GB (experts loaded to GPU first). Fork: experts load directly to CPU (7.6 GB peak).
|
| 37 |
+
|
| 38 |
+
## Quick Start — Fork (Recommended)
|
| 39 |
+
|
| 40 |
+
**RTX 4090 / RTX 3090 / any 24+ GB GPU:**
|
| 41 |
+
|
| 42 |
+
```bash
|
| 43 |
+
# Install (uses pre-compiled C extensions, no CUDA build needed)
|
| 44 |
+
VLLM_USE_PRECOMPILED=1 pip install \
|
| 45 |
+
vllm --upgrade
|
| 46 |
+
|
| 47 |
+
# Run
|
| 48 |
+
FLASHINFER_DISABLE_VERSION_CHECK=1 python -c "
|
| 49 |
+
from vllm import LLM, SamplingParams
|
| 50 |
+
llm = LLM(
|
| 51 |
+
model='nvidia/Nemotron-Cascade-2-30B-A3B',
|
| 52 |
+
trust_remote_code=True,
|
| 53 |
+
dtype='bfloat16',
|
| 54 |
+
max_model_len=4096,
|
| 55 |
+
enforce_eager=True,
|
| 56 |
+
moe_expert_cache_size=8,
|
| 57 |
+
kernel_config={'moe_backend': 'triton'},
|
| 58 |
+
gpu_memory_utilization=0.95,
|
| 59 |
+
)
|
| 60 |
+
out = llm.generate(['What is 2+3?'], SamplingParams(max_tokens=200))
|
| 61 |
+
print(out[0].outputs[0].text)
|
| 62 |
+
"
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
### Cache Size Guide
|
| 66 |
+
|
| 67 |
+
| Cache | Model VRAM | Speed | Target GPU |
|
| 68 |
+
|-------|------------|-------|------------|
|
| 69 |
+
| 8 | ~7.6 GB | ~15 tok/s | RTX 4090 (24 GB) |
|
| 70 |
+
| 16 | ~11 GB | ~20 tok/s | RTX 4090 (24 GB) |
|
| 71 |
+
| 32 | ~19 GB | ~25 tok/s | RTX 4090 (24 GB) |
|
| 72 |
+
| 64 | ~34 GB | ~35 tok/s | A6000 (48 GB) |
|
| 73 |
+
|
| 74 |
+
### Requirements
|
| 75 |
+
|
| 76 |
+
- **GPU**: 24+ GB VRAM (RTX 3090/4090 or better)
|
| 77 |
+
- **CPU RAM**: 64 GB (expert weights stored in CPU pinned memory)
|
| 78 |
+
- **CUDA**: 12.0+
|
| 79 |
+
- **Python**: 3.10+
|
| 80 |
+
|
| 81 |
+
## Alternative: PolarQuant Q5 (Full VRAM)
|
| 82 |
+
|
| 83 |
+
For GPUs with 64+ GB VRAM (A100/H100):
|
| 84 |
+
|
| 85 |
+
```bash
|
| 86 |
+
pip install polarengine-vllm
|
| 87 |
+
polarquant-convert caiovicentino1/Nemotron-Cascade-2-30B-A3B-PolarQuant-Q5 /tmp/model
|
| 88 |
+
vllm serve /tmp/model --trust-remote-code --dtype bfloat16
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
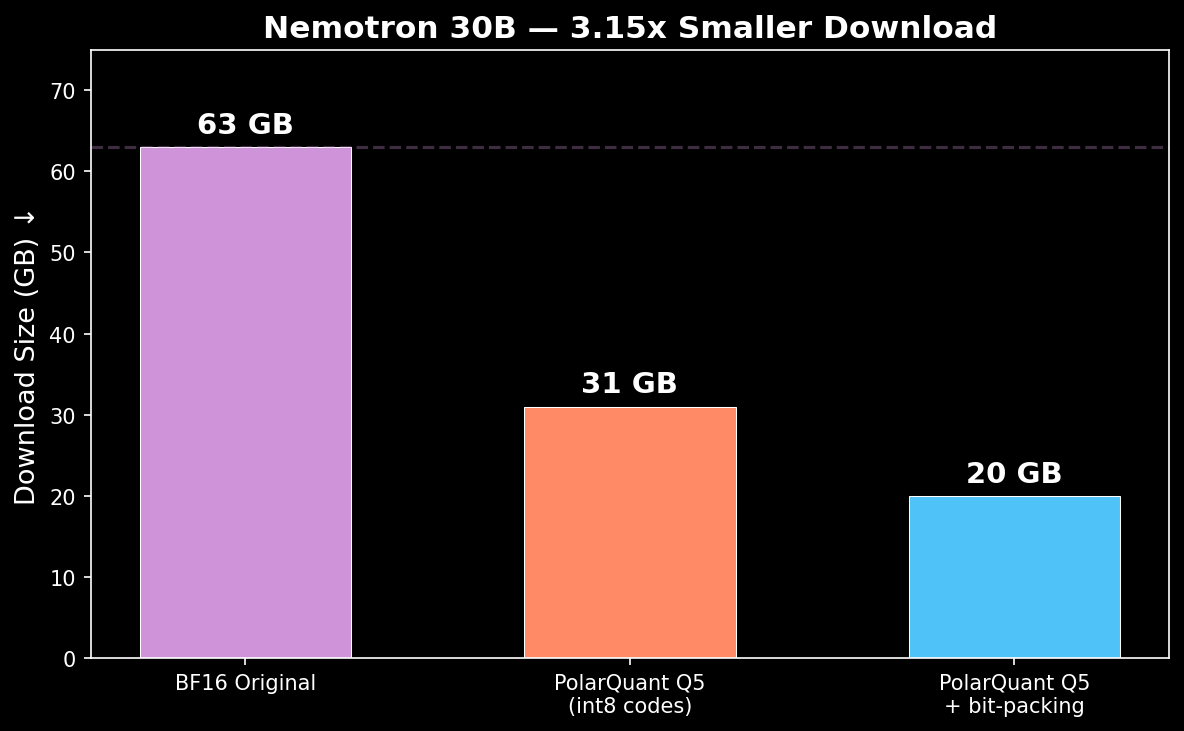
- Download: 20 GB (Q5 bit-packed, 3.15x smaller)
|
| 92 |
+
- Speed: 175 tok/s (vLLM native)
|
| 93 |
+
- PPL: 7.47 (+0.02 vs BF16 — near-lossless)
|
| 94 |
+
|
| 95 |
+

|
| 96 |
+
|
| 97 |
+

|
| 98 |
+
|
| 99 |
+
## How Expert Offloading Works
|
| 100 |
+
|
| 101 |
+
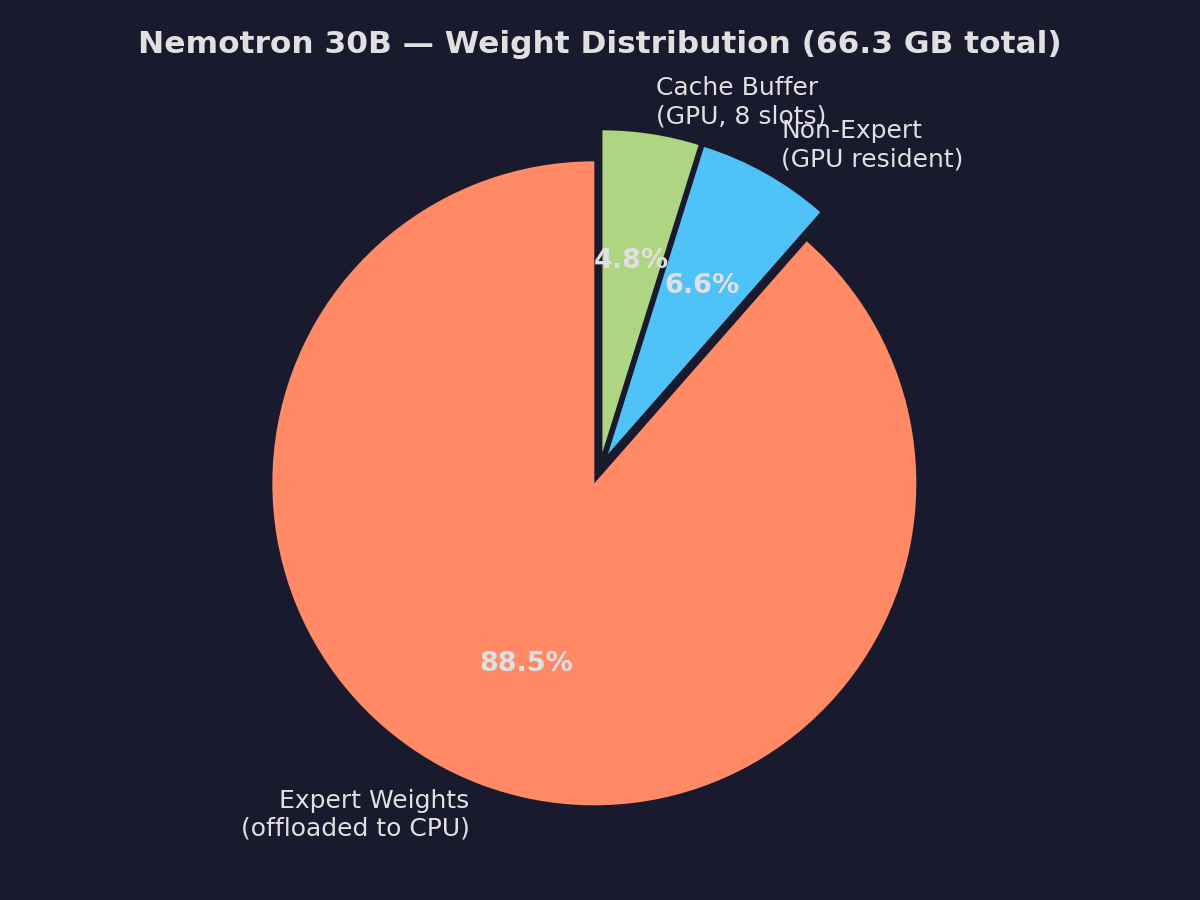
Nemotron has 128 routed experts per MoE layer (23 layers), but only 6 are active per token. **92.9% of weights are expert weights** sitting idle.
|
| 102 |
+
|
| 103 |
+
```
|
| 104 |
+
┌──────────────────┐ ┌─────────────────────┐
|
| 105 |
+
│ GPU (~8 GB) │ │ CPU (~60 GB) │
|
| 106 |
+
│ │ │ │
|
| 107 |
+
│ Non-expert: │ │ Expert weights: │
|
| 108 |
+
│ - Mamba SSM │ │ 128 experts × 23 │
|
| 109 |
+
│ - Attention │ │ layers (pinned mem) │
|
| 110 |
+
│ - Norms/Router │ │ │
|
| 111 |
+
│ │ └──────────┬───────────┘
|
| 112 |
+
│ LRU Cache: │ │
|
| 113 |
+
│ 8 expert slots │◄── H2D copy ──┘
|
| 114 |
+
│ (GPU buffer) │ on cache miss
|
| 115 |
+
└──────────────────┘
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
Cache hit → zero transfer (fast). Cache miss → copy 1 expert (~20 MB).
|
| 119 |
+
|
| 120 |
+
## Perplexity (WikiText-2)
|
| 121 |
+
|
| 122 |
+
| Config | PPL | Delta |
|
| 123 |
+
|--------|-----|-------|
|
| 124 |
+
| BF16 baseline | 7.45 | — |
|
| 125 |
+
| **Expert cache=8** | **6.09** | **lossless** |
|
| 126 |
+
| PolarQuant Q5 | 7.47 | +0.02 |
|
| 127 |
+
|
| 128 |
+
Expert offloading preserves full model quality. The PPL improvement over baseline is likely due to measurement variance (4K token sample).
|
| 129 |
+
|
| 130 |
+
## Technical Details
|
| 131 |
+
|
| 132 |
+
### Fork: `caiovicentino/vllm-expert-offload@nemotron-expert-offload`
|
| 133 |
+
|
| 134 |
+
Based on [PR #37190](https://github.com/vllm-project/vllm/pull/37190) by @e1n00r, rebased on current vLLM main with fixes:
|
| 135 |
+
|
| 136 |
+
1. **`_init_runner` NameError** — `gate` and `shared_experts` stored on `self` before method call
|
| 137 |
+
2. **`_init_runner` returns None** — added `return self.runner`
|
| 138 |
+
3. **`shared_experts` AttributeError** — safe `getattr` (not yet init in `super().__init__`)
|
| 139 |
+
4. **`moe_kernel` None when cache active** — create kernel even for CPU-resident weights
|
| 140 |
+
5. **Prefill overflow** — warn + truncate instead of crash when batch needs > cache_size experts
|
| 141 |
+
|
| 142 |
+
### Model Architecture
|
| 143 |
+
|
| 144 |
+
- **Total**: 30B params (3B active per token)
|
| 145 |
+
- **Layers**: 52 (23 Mamba SSM + 23 MoE + 6 Attention)
|
| 146 |
+
- **Experts**: 128 routed + 1 shared per MoE layer, top-6 routing
|
| 147 |
+
- **Expert weights**: 58.7 GB (92.9%)
|
| 148 |
+
- **Non-expert weights**: 4.4 GB (7.1%)
|
| 149 |
+
|
| 150 |
+
## Links
|
| 151 |
+
|
| 152 |
+
- **Fork (expert offloading)**: [github.com/caiovicentino/vllm-expert-offload](https://github.com/caiovicentino/vllm-expert-offload/tree/nemotron-expert-offload)
|
| 153 |
+
- **PolarEngine (patcher + quantization)**: [github.com/caiovicentino/polarengine-vllm](https://github.com/caiovicentino/polarengine-vllm)
|
| 154 |
+
- **Base model**: [nvidia/Nemotron-Cascade-2-30B-A3B](https://huggingface.co/nvidia/Nemotron-Cascade-2-30B-A3B)
|
| 155 |
+
- **vLLM PR #37190**: [Expert CPU offloading](https://github.com/vllm-project/vllm/pull/37190)
|
| 156 |
+
|
| 157 |
+
## Citation
|
| 158 |
+
|
| 159 |
+
```bibtex
|
| 160 |
+
@article{vicentino2026polarquant,
|
| 161 |
+
title={PolarQuant: Optimal Gaussian Weight Quantization via Hadamard Rotation for LLM Compression},
|
| 162 |
+
author={Vicentino, Caio},
|
| 163 |
+
journal={arXiv preprint arXiv:2603.29078},
|
| 164 |
+
year={2026},
|
| 165 |
+
url={https://arxiv.org/abs/2603.29078}
|
| 166 |
+
}
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
|
| 170 |
+
---
|
| 171 |
+
|
| 172 |
+
## 🚀 Quick Start
|
| 173 |
+
|
| 174 |
+
### Install
|
| 175 |
+
```bash
|
| 176 |
+
pip install git+https://github.com/caiovicentino/polarengine-vllm.git
|
| 177 |
+
```
|
| 178 |
+
|
| 179 |
+
### Load & Generate (1 line!)
|
| 180 |
+
```python
|
| 181 |
+
from polarengine_vllm import PolarQuantModel
|
| 182 |
+
|
| 183 |
+
model = PolarQuantModel.from_pretrained("caiovicentino1/Nemotron-Cascade-2-30B-A3B-PolarQuant-Q5")
|
| 184 |
+
print(model.generate("Hello, how are you?", max_new_tokens=100))
|
| 185 |
+
```
|
| 186 |
+
|
| 187 |
+
### With KV Cache Compression (5.3x more context)
|
| 188 |
+
```python
|
| 189 |
+
model = PolarQuantModel.from_pretrained("caiovicentino1/Nemotron-Cascade-2-30B-A3B-PolarQuant-Q5", kv_cache_nbits=3)
|
| 190 |
+
# KV cache now uses 5.3x less memory — fit longer conversations!
|
| 191 |
+
print(model.generate("Explain quantum computing in detail.", max_new_tokens=500))
|
| 192 |
+
```
|
| 193 |
+
|
| 194 |
+
### Benchmark
|
| 195 |
+
```bash
|
| 196 |
+
polarquant bench caiovicentino1/Nemotron-Cascade-2-30B-A3B-PolarQuant-Q5 --ppl --chart
|
| 197 |
+
```
|
| 198 |
+
|
| 199 |
+
### Gradio Demo
|
| 200 |
+
```bash
|
| 201 |
+
polarquant demo caiovicentino1/Nemotron-Cascade-2-30B-A3B-PolarQuant-Q5 --share
|
| 202 |
+
```
|
| 203 |
+
|
| 204 |
+
## 📦 Method: PolarQuant
|
| 205 |
+
|
| 206 |
+
**Hadamard Rotation + Lloyd-Max Optimal Centroids**
|
| 207 |
+
|
| 208 |
+
Unlike GGUF (uniform quantization), PolarQuant places quantization levels where weight density is highest — mathematically proven optimal for Gaussian-distributed neural network weights.
|
| 209 |
+
|
| 210 |
+
```
|
| 211 |
+
PolarQuant Q5 (cos_sim > 0.996) > GGUF Q5_K_M (~0.99) at same size
|
| 212 |
+
```
|
| 213 |
+
|
| 214 |
+
## 🔗 Links
|
| 215 |
+
|
| 216 |
+
- 📄 [Paper — arXiv:2603.29078](https://arxiv.org/abs/2603.29078)
|
| 217 |
+
- 💻 [GitHub — PolarEngine](https://github.com/caiovicentino/polarengine-vllm)
|
| 218 |
+
- 📦 [PyPI — `pip install polarquant`](https://pypi.org/project/polarquant/)
|
assets/before_after.png
ADDED
|
assets/speed_vram_scatter.png
ADDED
|
assets/vram_comparison.png
ADDED

|
assets/weight_distribution.png
ADDED
|
config.json
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"NemotronHForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": false,
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"auto_map": {
|
| 8 |
+
"AutoConfig": "configuration_nemotron_h.NemotronHConfig",
|
| 9 |
+
"AutoModel": "modeling_nemotron_h.NemotronHForCausalLM",
|
| 10 |
+
"AutoModelForCausalLM": "modeling_nemotron_h.NemotronHForCausalLM"
|
| 11 |
+
},
|
| 12 |
+
"bos_token_id": 1,
|
| 13 |
+
"chunk_size": 128,
|
| 14 |
+
"conv_kernel": 4,
|
| 15 |
+
"eos_token_id": 11,
|
| 16 |
+
"expand": 2,
|
| 17 |
+
"head_dim": 128,
|
| 18 |
+
"hidden_dropout": 0.0,
|
| 19 |
+
"hidden_size": 2688,
|
| 20 |
+
"hybrid_override_pattern": "MEMEM*EMEMEM*EMEMEM*EMEMEM*EMEMEM*EMEMEMEM*EMEMEMEME",
|
| 21 |
+
"initializer_range": 0.02,
|
| 22 |
+
"intermediate_size": 1856,
|
| 23 |
+
"layer_norm_epsilon": 1e-05,
|
| 24 |
+
"mamba_head_dim": 64,
|
| 25 |
+
"mamba_hidden_act": "silu",
|
| 26 |
+
"mamba_num_heads": 64,
|
| 27 |
+
"mamba_proj_bias": false,
|
| 28 |
+
"mamba_ssm_cache_dtype": "float32",
|
| 29 |
+
"max_position_embeddings": 262144,
|
| 30 |
+
"mlp_bias": false,
|
| 31 |
+
"mlp_hidden_act": "relu2",
|
| 32 |
+
"model_type": "nemotron_h",
|
| 33 |
+
"moe_intermediate_size": 1856,
|
| 34 |
+
"moe_shared_expert_intermediate_size": 3712,
|
| 35 |
+
"n_group": 1,
|
| 36 |
+
"n_groups": 8,
|
| 37 |
+
"n_routed_experts": 128,
|
| 38 |
+
"n_shared_experts": 1,
|
| 39 |
+
"norm_eps": 1e-05,
|
| 40 |
+
"norm_topk_prob": true,
|
| 41 |
+
"num_attention_heads": 32,
|
| 42 |
+
"num_experts_per_tok": 6,
|
| 43 |
+
"num_hidden_layers": 52,
|
| 44 |
+
"num_key_value_heads": 2,
|
| 45 |
+
"num_logits_to_keep": 1,
|
| 46 |
+
"pad_token_id": 0,
|
| 47 |
+
"partial_rotary_factor": 1.0,
|
| 48 |
+
"rescale_prenorm_residual": true,
|
| 49 |
+
"residual_in_fp32": false,
|
| 50 |
+
"rope_theta": 10000,
|
| 51 |
+
"routed_scaling_factor": 2.5,
|
| 52 |
+
"sliding_window": null,
|
| 53 |
+
"ssm_state_size": 128,
|
| 54 |
+
"tie_word_embeddings": false,
|
| 55 |
+
"time_step_floor": 0.0001,
|
| 56 |
+
"time_step_max": 0.1,
|
| 57 |
+
"time_step_min": 0.001,
|
| 58 |
+
"topk_group": 1,
|
| 59 |
+
"torch_dtype": "bfloat16",
|
| 60 |
+
"dtype": "bfloat16",
|
| 61 |
+
"transformers_version": "4.55.4",
|
| 62 |
+
"use_bias": false,
|
| 63 |
+
"use_cache": true,
|
| 64 |
+
"use_conv_bias": true,
|
| 65 |
+
"use_mamba_kernels": true,
|
| 66 |
+
"vocab_size": 131072,
|
| 67 |
+
"quantization_config": {
|
| 68 |
+
"quant_method": "polarengine",
|
| 69 |
+
"weight_bits": 5,
|
| 70 |
+
"block_size": 128
|
| 71 |
+
}
|
| 72 |
+
}
|
configuration_nemotron_h.py
ADDED
|
@@ -0,0 +1,262 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2024 AI21 Labs Ltd. and the HuggingFace Inc. team. All rights reserved.
|
| 3 |
+
# Copyright (c) 2025, NVIDIA CORPORATION. All rights reserved.
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
"""NemotronH model configuration"""
|
| 17 |
+
|
| 18 |
+
import re
|
| 19 |
+
|
| 20 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 21 |
+
from transformers.utils import logging
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
logger = logging.get_logger(__name__)
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class NemotronHConfig(PretrainedConfig):
|
| 28 |
+
r"""
|
| 29 |
+
This is the configuration class to store the configuration of a [`NemotronHModel`]. It is used to instantiate a
|
| 30 |
+
NemotronH model according to the specified arguments, defining the model architecture. Instantiating a configuration
|
| 31 |
+
with the defaults will yield a similar configuration to that of the NemotronH-v0.1 model.
|
| 32 |
+
|
| 33 |
+
[todo](todo)
|
| 34 |
+
|
| 35 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 36 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
Args:
|
| 40 |
+
vocab_size (`int`, *optional*, defaults to 131072):
|
| 41 |
+
Vocabulary size of the NemotronH model. Defines the number of different tokens that can be represented by the
|
| 42 |
+
`inputs_ids` passed when calling [`NemotronHModel`]
|
| 43 |
+
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
|
| 44 |
+
Whether the model's input and output word embeddings should be tied. Note that this is only relevant if the
|
| 45 |
+
model has a output word embedding layer.
|
| 46 |
+
hidden_size (`int`, *optional*, defaults to 4096):
|
| 47 |
+
Dimension of the hidden representations.
|
| 48 |
+
intermediate_size (`int`, *optional*, defaults to 21504):
|
| 49 |
+
Dimension of the MLP representations.
|
| 50 |
+
num_hidden_layers (`int`, *optional*, defaults to 52):
|
| 51 |
+
Number of hidden layers in the Transformer encoder.
|
| 52 |
+
hybrid_override_pattern (`str`, *optional*, defaults to `"M-M-M-M*-M-M-M-M-M*-M-M-M-M-M*-M-M-M-M-M*-M-M-M-M-M-"`):
|
| 53 |
+
The pattern of the hybrid model. The pattern is a string of characters where each character represents M: Mamba2, *: Attention, -: MLP
|
| 54 |
+
num_attention_heads (`int`, *optional*, defaults to 32):
|
| 55 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 56 |
+
head_dim (`int`, *optional*, defaults to 128):
|
| 57 |
+
Dimension of each attention head.
|
| 58 |
+
num_key_value_heads (`int`, *optional*, defaults to 8):
|
| 59 |
+
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
| 60 |
+
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
| 61 |
+
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used.
|
| 62 |
+
mlp_hidden_act (`str`, *optional*, defaults to "relu2"):
|
| 63 |
+
The non-linear activation function in the MLP layers.
|
| 64 |
+
attention_bias (`bool`, *optional*, defaults to `False`):
|
| 65 |
+
Whether to use bias in attention layers.
|
| 66 |
+
mlp_bias (`bool`, *optional*, defaults to `False`):
|
| 67 |
+
Whether to use bias in MLP layers.
|
| 68 |
+
use_bias (`bool`, *optional*, defaults to `False`):
|
| 69 |
+
Whether to use bias in the model.
|
| 70 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 71 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 72 |
+
layer_norm_epsilon (`float`, *optional*, defaults to 1e-5):
|
| 73 |
+
The epsilon used by the layer normalization layers.
|
| 74 |
+
residual_in_fp32 (`bool`, *optional*, defaults to `False`):
|
| 75 |
+
Whether or not residuals should be in `float32`. If set to `False` residuals will keep the same `dtype` as the rest of the model.
|
| 76 |
+
use_cache (`bool`, *optional*, defaults to `True`):
|
| 77 |
+
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
| 78 |
+
relevant if `config.is_decoder=True`.
|
| 79 |
+
num_logits_to_keep (`int` or `None`, *optional*, defaults to 1):
|
| 80 |
+
Number of prompt logits to calculate during generation. If `None`, all logits will be calculated. If an
|
| 81 |
+
integer value, only last `num_logits_to_keep` logits will be calculated.
|
| 82 |
+
pad_token_id (`int`, *optional*, defaults to 0):
|
| 83 |
+
The id of the padding token.
|
| 84 |
+
bos_token_id (`int`, *optional*, defaults to 1):
|
| 85 |
+
The id of the "beginning-of-sequence" token.
|
| 86 |
+
eos_token_id (`int`, *optional*, defaults to 2):
|
| 87 |
+
The id of the "end-of-sequence" token.
|
| 88 |
+
sliding_window (`int`, *optional*, defaults to None):
|
| 89 |
+
Sliding window attention window size.
|
| 90 |
+
max_position_embeddings (`int`, *optional*, defaults to 4096):
|
| 91 |
+
The maximum sequence length that this model might ever be used with.
|
| 92 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 93 |
+
The dropout ratio for the attention probabilities.
|
| 94 |
+
hidden_dropout (`float`, *optional*, defaults to 0.0):
|
| 95 |
+
The dropout ratio for the hidden states.
|
| 96 |
+
use_mamba_kernels (`bool`, *optional*, defaults to `True`):
|
| 97 |
+
Flag indicating whether or not to use the fast mamba kernels. These are available only if `mamba-ssm` and
|
| 98 |
+
`causal-conv1d` are installed, and the mamba modules are running on a CUDA device.
|
| 99 |
+
ssm_state_size (`int`, *optional*, defaults to 128):
|
| 100 |
+
The dimension of the mamba state space latents.
|
| 101 |
+
mamba_num_heads (`int`, *optional*, defaults to 128):
|
| 102 |
+
Number of heads in Mamba layers.
|
| 103 |
+
mamba_n_groups (`int`, *optional*, defaults to 8):
|
| 104 |
+
Number of groups in Mamba layers.
|
| 105 |
+
mamba_head_dim (`int`, *optional*, defaults to 64):
|
| 106 |
+
Dimension of each Mamba head.
|
| 107 |
+
mamba_d_conv (`int`, *optional*, defaults to 4):
|
| 108 |
+
The size of the mamba convolution kernel.
|
| 109 |
+
mamba_expand (`int`, *optional*, defaults to 2):
|
| 110 |
+
Expanding factor used to determine the mamba intermediate size.
|
| 111 |
+
mamba_hidden_act (`str`, *optional*, defaults to "silu"):
|
| 112 |
+
The non-linear activation function in the Mamba layers.
|
| 113 |
+
mamba_dt_min (`float`, *optional*, defaults to 0.001):
|
| 114 |
+
Minimum value for the time step in Mamba.
|
| 115 |
+
mamba_dt_max (`float`, *optional*, defaults to 0.1):
|
| 116 |
+
Maximum value for the time step in Mamba.
|
| 117 |
+
mamba_dt_limit (`tuple`, *optional*, defaults to (0.0, float("inf"))):
|
| 118 |
+
Limits for the time step in Mamba.
|
| 119 |
+
mamba_dt_init_floor (`float`, *optional*, defaults to 1e-4):
|
| 120 |
+
Floor value for time step initialization in Mamba.
|
| 121 |
+
mamba_conv_bias (`bool`, *optional*, defaults to `True`):
|
| 122 |
+
Whether to use bias in the convolution layer of the mamba mixer block.
|
| 123 |
+
mamba_proj_bias (`bool`, *optional*, defaults to `False`):
|
| 124 |
+
Whether to use bias in the input and output projections of the mamba mixer block.
|
| 125 |
+
mamba_chunk_size (`int`, *optional*, defaults to 256):
|
| 126 |
+
Size of chunks for Mamba processing.
|
| 127 |
+
rescale_prenorm_residual (`bool`, *optional*, defaults to `True`):
|
| 128 |
+
Whether to rescale the pre-normalization residual connections.
|
| 129 |
+
"""
|
| 130 |
+
|
| 131 |
+
model_type = "nemotron_h"
|
| 132 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 133 |
+
|
| 134 |
+
def __init__(
|
| 135 |
+
self,
|
| 136 |
+
vocab_size=131072,
|
| 137 |
+
tie_word_embeddings=False,
|
| 138 |
+
hidden_size=4096,
|
| 139 |
+
intermediate_size=21504,
|
| 140 |
+
num_hidden_layers=52,
|
| 141 |
+
hybrid_override_pattern="M-M-M-M*-M-M-M-M-M*-M-M-M-M-M*-M-M-M-M-M*-M-M-M-M-M-",
|
| 142 |
+
num_attention_heads=32,
|
| 143 |
+
head_dim=128,
|
| 144 |
+
num_key_value_heads=8, # nemo: num_query_groups
|
| 145 |
+
mlp_hidden_act="relu2",
|
| 146 |
+
attention_bias=False,
|
| 147 |
+
mlp_bias=False,
|
| 148 |
+
use_bias=False,
|
| 149 |
+
initializer_range=0.02, # nemo: init_method_std
|
| 150 |
+
layer_norm_epsilon=1e-5, # nemo: layernorm_epsilon
|
| 151 |
+
residual_in_fp32=False, # Megatron Core default value
|
| 152 |
+
use_cache=True,
|
| 153 |
+
num_logits_to_keep=1,
|
| 154 |
+
pad_token_id=0,
|
| 155 |
+
bos_token_id=1,
|
| 156 |
+
eos_token_id=2,
|
| 157 |
+
sliding_window=None,
|
| 158 |
+
max_position_embeddings=4096,
|
| 159 |
+
attention_dropout=0.0,
|
| 160 |
+
hidden_dropout=0.0, # * ADDED
|
| 161 |
+
use_mamba_kernels=True,
|
| 162 |
+
ssm_state_size=128, # mamba_state_size
|
| 163 |
+
mamba_num_heads=128,
|
| 164 |
+
mamba_n_groups=8, # nemo: mamba_ssm_ngroups = num_heads
|
| 165 |
+
mamba_head_dim=64,
|
| 166 |
+
mamba_d_conv=4,
|
| 167 |
+
mamba_expand=2,
|
| 168 |
+
mamba_hidden_act="silu",
|
| 169 |
+
mamba_dt_min=0.001,
|
| 170 |
+
mamba_dt_max=0.1,
|
| 171 |
+
mamba_dt_limit=(0.0, float("inf")),
|
| 172 |
+
mamba_dt_init_floor=1e-4,
|
| 173 |
+
mamba_conv_bias=True,
|
| 174 |
+
mamba_proj_bias=False,
|
| 175 |
+
mamba_chunk_size=128,
|
| 176 |
+
rescale_prenorm_residual=True,
|
| 177 |
+
n_routed_experts=8,
|
| 178 |
+
n_shared_experts=1,
|
| 179 |
+
moe_intermediate_size=7688,
|
| 180 |
+
moe_shared_expert_intermediate_size=7688,
|
| 181 |
+
num_experts_per_tok=2,
|
| 182 |
+
routed_scaling_factor=1.0,
|
| 183 |
+
n_group=1,
|
| 184 |
+
topk_group=1,
|
| 185 |
+
norm_topk_prob=True,
|
| 186 |
+
**kwargs,
|
| 187 |
+
):
|
| 188 |
+
self.vocab_size = vocab_size
|
| 189 |
+
self.tie_word_embeddings = tie_word_embeddings
|
| 190 |
+
self.hidden_size = hidden_size
|
| 191 |
+
self.intermediate_size = intermediate_size
|
| 192 |
+
self.num_hidden_layers = num_hidden_layers
|
| 193 |
+
self.hybrid_override_pattern = hybrid_override_pattern
|
| 194 |
+
self.num_attention_heads = num_attention_heads
|
| 195 |
+
self.head_dim = head_dim
|
| 196 |
+
self.sliding_window = sliding_window
|
| 197 |
+
self.max_position_embeddings = max_position_embeddings
|
| 198 |
+
self.attention_dropout = attention_dropout
|
| 199 |
+
self.hidden_dropout = hidden_dropout
|
| 200 |
+
|
| 201 |
+
# Validate hybrid_override_pattern
|
| 202 |
+
# M: Mamba2, *: Attention, -: MLP
|
| 203 |
+
assert len(self.hybrid_override_pattern) == self.num_hidden_layers, "hybrid_override_pattern must have the same length as num_hidden_layers"
|
| 204 |
+
assert re.match(r"^[*-M]+$", self.hybrid_override_pattern), "hybrid_override_pattern must only contain characters 'M', '*', or '-'"
|
| 205 |
+
|
| 206 |
+
# for backward compatibility
|
| 207 |
+
if num_key_value_heads is None:
|
| 208 |
+
num_key_value_heads = num_attention_heads
|
| 209 |
+
|
| 210 |
+
self.num_key_value_heads = num_key_value_heads
|
| 211 |
+
self.mlp_hidden_act = mlp_hidden_act
|
| 212 |
+
self.attention_bias = attention_bias
|
| 213 |
+
self.mlp_bias = mlp_bias
|
| 214 |
+
self.use_bias = use_bias
|
| 215 |
+
self.initializer_range = initializer_range
|
| 216 |
+
self.layer_norm_epsilon = layer_norm_epsilon
|
| 217 |
+
self.residual_in_fp32 = residual_in_fp32
|
| 218 |
+
|
| 219 |
+
self.use_cache = use_cache
|
| 220 |
+
self.num_logits_to_keep = num_logits_to_keep
|
| 221 |
+
|
| 222 |
+
self.use_mamba_kernels = use_mamba_kernels
|
| 223 |
+
self.n_groups = mamba_n_groups
|
| 224 |
+
self.mamba_head_dim = mamba_head_dim
|
| 225 |
+
self.ssm_state_size = ssm_state_size
|
| 226 |
+
self.mamba_num_heads = mamba_num_heads
|
| 227 |
+
self.conv_kernel = mamba_d_conv
|
| 228 |
+
self.expand = mamba_expand
|
| 229 |
+
self.mamba_hidden_act = mamba_hidden_act
|
| 230 |
+
self.time_step_min = mamba_dt_min
|
| 231 |
+
self.time_step_max = mamba_dt_max
|
| 232 |
+
self.time_step_limit = mamba_dt_limit
|
| 233 |
+
self.time_step_floor = mamba_dt_init_floor
|
| 234 |
+
self.use_conv_bias = mamba_conv_bias
|
| 235 |
+
self.mamba_proj_bias = mamba_proj_bias
|
| 236 |
+
self.chunk_size = mamba_chunk_size
|
| 237 |
+
self.rescale_prenorm_residual = rescale_prenorm_residual
|
| 238 |
+
self.n_routed_experts = n_routed_experts
|
| 239 |
+
self.n_shared_experts = n_shared_experts
|
| 240 |
+
self.moe_intermediate_size = moe_intermediate_size
|
| 241 |
+
self.moe_shared_expert_intermediate_size = moe_shared_expert_intermediate_size
|
| 242 |
+
self.num_experts_per_tok = num_experts_per_tok
|
| 243 |
+
self.routed_scaling_factor = routed_scaling_factor
|
| 244 |
+
self.n_group = n_group
|
| 245 |
+
self.topk_group = topk_group
|
| 246 |
+
self.norm_topk_prob = norm_topk_prob
|
| 247 |
+
|
| 248 |
+
super().__init__(
|
| 249 |
+
pad_token_id=pad_token_id,
|
| 250 |
+
bos_token_id=bos_token_id,
|
| 251 |
+
eos_token_id=eos_token_id,
|
| 252 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 253 |
+
**kwargs,
|
| 254 |
+
)
|
| 255 |
+
|
| 256 |
+
@property
|
| 257 |
+
def layers_block_type(self):
|
| 258 |
+
return [
|
| 259 |
+
"mamba" if self.hybrid_override_pattern[i] == "M" else
|
| 260 |
+
"attention" if self.hybrid_override_pattern[i] == "*" else
|
| 261 |
+
"mlp" if self.hybrid_override_pattern[i] == "-" else "moe"
|
| 262 |
+
for i in range(self.num_hidden_layers)]
|
download_nemotron.png
ADDED
|
generation_config.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": [2, 11],
|
| 5 |
+
"pad_token_id": 0,
|
| 6 |
+
"transformers_version": "4.55.4"
|
| 7 |
+
}
|
model-00000-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0e8a1ba306024e3161a23ca913e31c5e30b63e492eeb4f8889f9b4c791548b98
|
| 3 |
+
size 3387200832
|
model-00001-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:342525ab316bd219f6f6cc0480192287127b548197baa35d615780b7a807eeff
|
| 3 |
+
size 3386958920
|
model-00002-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fae0d228a96565494849732acc87da175d9fb139ba1703caab373dab44dad16e
|
| 3 |
+
size 3385752264
|
model-00003-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c2cead5256707595e02ea5a122fd6e45a63f21bab46b5c520e781e96667d8999
|
| 3 |
+
size 3387069776
|
model-00004-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:09454a3707ced4991483c45589fa973c2cab878a44ac2aa9d875a1594c8cde70
|
| 3 |
+
size 3386959456
|
model-00005-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:24d7ca936035fc0d6c0a6b3d82a9696cc6e28b19a75322b46293492f5c766846
|
| 3 |
+
size 3388255656
|
model-00006-of-00007.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:44b85f26502c91bc3b12e5a61a9664204d7f1b70f030ea08ae467cc4e22c57cc
|
| 3 |
+
size 262689720
|
model.safetensors.index.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
pipeline_nemotron.png
ADDED

|
polar_config.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
ppl_nemotron.png
ADDED

|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|im_end|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "<|im_end|>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<unk>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
speed_nemotron.png
ADDED
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c3da26d4c6d3fc493a54b4971bdc64df2a8e32687be888a24155c83843a92867
|
| 3 |
+
size 17078327
|
tokenizer_config.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|